Customize Text Segmentation
- Stephan Böhmig
- lpercetti_wordbee (Deactivated)
Owned by Stephan Böhmig
The Beebox uses preset SRX rules to segment text content into sentences and paragraphs.
SRX is a commonly used standard for coding rules to split text into small constituents such as sentences.
Prepare your rules:
- Create a separate SRX file per each language to customize: en.srx, fr.srx, ...
- The Beebox uses general rules that are prepended to each language specific rule set. To customize the general rules create: default.srx
Install your rules:
- Copy your *.srx files to "c:\beebox\data\srx"
Notes:- The "c:\beebox" directory may be different in your installation
- The subfolders "data\srx" doesn't exist by default, you can create them by yourself.
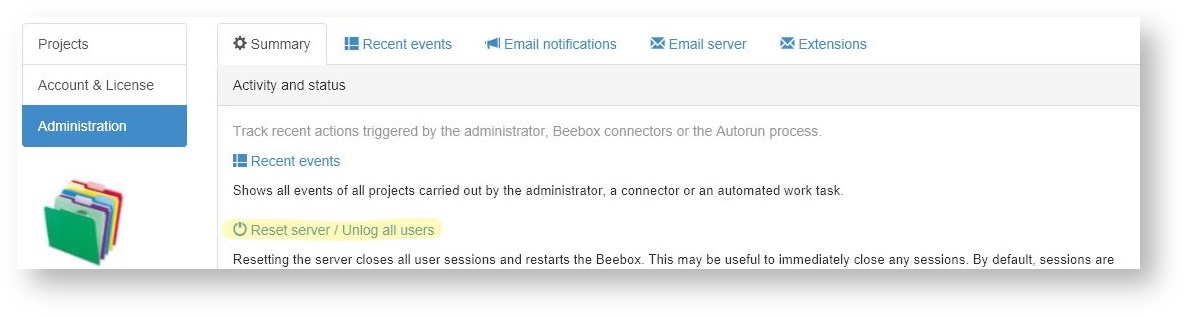
- Click the Reset Server link on the Administration page for changes to take effect:
Beebox default.srx:
The pre-installed default rules are:
<srx xmlns="http://www.lisa.org/srx20" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="2.0">
<header segmentsubflows="yes" cascade="no">
<formathandle type="start" include="yes" />
<formathandle type="end" include="yes" />
<formathandle type="isolated" include="yes" />
</header>
<body>
<languagerules>
<languagerule xmlns="http://www.lisa.org/srx20" languagerulename="default">
<rule break="yes">
<beforebreak>\s[0-9]\.</beforebreak>
<afterbreak>\s+\p{Lu}</afterbreak>
</rule>
<rule break="no">
<beforebreak>\s[\p{Nd}IiVvXxMmCc]{1,4}\.</beforebreak>
<afterbreak>\s+\p{Ll}</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\s[\p{Nd}IiVvXxMmCc]{1,4}\.</beforebreak>
<afterbreak>\s+\p{Lu}</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\u2029</beforebreak>
<afterbreak />
</rule>
<rule break="no">
<beforebreak>\s(\p{L}\.){2,}</beforebreak>
<afterbreak>\s\p{Ll}</afterbreak>
</rule>
<rule break="no">
<beforebreak>[\(\[\{]+\s*\.</beforebreak>
<afterbreak>\s*[\)\]\}]+</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\s[\p{Ll}_]+\.</beforebreak>
<afterbreak>\s+[\"\'\[\(\)\`]</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\p{L}{2,}\.[\"\'\)\`]</beforebreak>
<afterbreak>\s[\"\'\)\`]?\p{Lu}</afterbreak>
</rule>
<rule break="no">
<beforebreak>\s\p{Lu}\p{Ll}+\s\p{Lu}\.</beforebreak>
<afterbreak>\s\p{Lu}\p{Ll}+</afterbreak>
</rule>
<rule break="yes">
<beforebreak>(^|\s)+\p{L}\.</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="no">
<beforebreak>\s[^\p{L}]\p{L}\.</beforebreak>
<afterbreak />
</rule>
<rule break="no">
<beforebreak>\([^\)]{1,40}[\.\;\:]</beforebreak>
<afterbreak>\s[^\)]{1,40}\)</afterbreak>
</rule>
<rule break="no">
<beforebreak>\"[^\"]{1,60}[\;\:]</beforebreak>
<afterbreak>\s[^\"\.]{1,120}\"</afterbreak>
</rule>
<rule break="no">
<beforebreak>\s\p{Lu}\p{L}{1,7}\.</beforebreak>
<afterbreak>\s(\p{L}{1,7}\.\s)+</afterbreak>
</rule>
<rule break="no">
<beforebreak>\s\:</beforebreak>
<afterbreak>\s+[0-9]+</afterbreak>
</rule>
<rule break="no">
<beforebreak>\;</beforebreak>
<afterbreak>\s+\p{Ll}</afterbreak>
</rule>
<rule break="no">
<beforebreak>\:</beforebreak>
<afterbreak>\s+[^\"\'\(\„].{1,40}(\.|$)</afterbreak>
</rule>
<rule break="no">
<beforebreak>(^|\.)\s*.{1,15}\:</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="no">
<beforebreak>^\.{1,9}\:</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="no">
<beforebreak>\.+</beforebreak>
<afterbreak>[\"\"\'"\)]?\s\p{Ll}</afterbreak>
</rule>
<rule break="no">
<beforebreak>[\(\[\{]\s*.{0,3}[\.\?\!\;\:]+\s*[\)\]\}]\s</beforebreak>
<afterbreak />
</rule>
<rule break="yes">
<beforebreak>[\.\?\!\;\:]+[\"\"\'"\)]?</beforebreak>
<afterbreak>\s</afterbreak>
</rule>
<rule break="yes">
<beforebreak>\n</beforebreak>
<afterbreak>\S\t+</afterbreak>
</rule>
</languagerule>
</languagerules>
<maprules>
<languagemap languagepattern=".*" languagerulename="default" />
</maprules>
</body>
</srx>
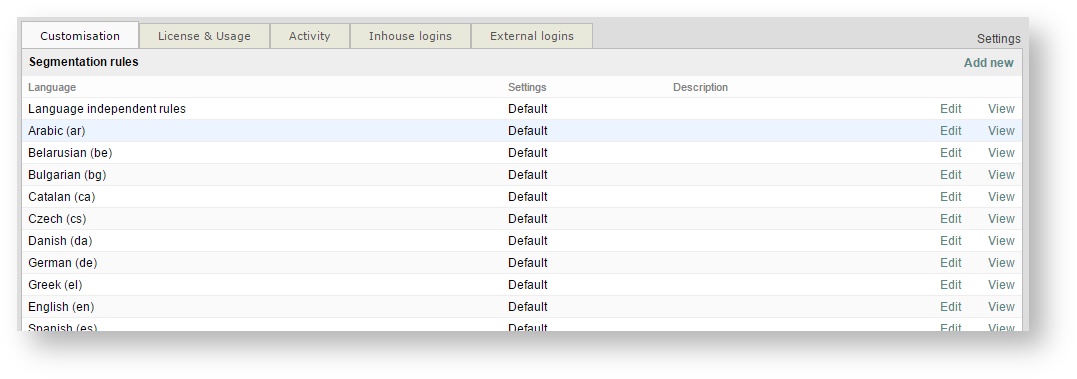
The language specific rules in the Beebox can be downloaded from a Wordbee Translator platform (if you do not have one, register for a trial).
Go to Settings, then Segmentation Rules and click View to start download:
Copyright Wordbee - Buzzin' Outside the Box since 2008